
Um guia para corrigir erros do Google Search Console em 2023
O Google Search Console é um aplicativo gratuito que permite identificar, solucionar problemas e resolver quaisquer problemas que o Google possa encontrar ao rastrear e tentar indexar seu site nos resultados de pesquisa. Ele também pode fornecer uma janela em que as páginas estão bem classificadas e quais páginas o Google optou por ignorar.

No vídeo abaixo, oferecemos uma rápida visão geral de alto nível da ferramenta e dos relatórios que o Google Search Console fornece:
Um dos recursos mais poderosos da ferramenta é o Relatório de Cobertura do Índice . Ele mostra uma lista de todas as páginas do seu site que o Google tentou rastrear e indexar, juntamente com quaisquer problemas encontrados ao longo do caminho.
Quando o Google está rastreando seu site, isso significa que suas páginas estão sendo descobertas e analisadas para determinar se suas informações são dignas de serem indexadas. Indexação significa que essas páginas foram analisadas pelo rastreador do Google (“Googlebot”) e armazenadas em servidores de indexação, tornando-as qualificadas para serem consultadas pelos mecanismos de pesquisa.
Se você não é a pessoa mais técnica do mundo, alguns dos erros que provavelmente encontrará podem deixá-lo coçando a cabeça. Queríamos torná-lo um pouco mais fácil, então reunimos este conjunto de dicas úteis para guiá-lo ao longo do caminho. Também exploraremos os relatórios de usabilidade em dispositivos móveis e principais métricas da Web.
Antes de nos aprofundarmos em cada um dos problemas, aqui está um rápido resumo do que é o Google Search Console e como você pode começar a usá-lo.
Introdução ao Search Console
Verificação de domínio
Primeiras coisas primeiro: se você ainda não o fez, certifique-se de verificar a propriedade do seu site no Google Search Console. Esta etapa é altamente recomendável, pois permite que você veja todos os subdomínios que se enquadram em seu site principal.
Certifique-se de verificar todas as versões do seu domínio. Isso inclui:
- http://yourdomain.com
- https://yourdomain.com
- http://www.yourdomain.com
- https://www.yourdomain.com
- E quaisquer outros subdomínios que não sejam www, incluindo blog.yourdomain.com, info.yourdomain.com, etc.
O Google trata cada uma dessas variações como um site separado, portanto, se você não verificar cada versão, há uma boa chance de perder algumas informações importantes.
Navegando no relatório de cobertura do índice
Depois de verificar seu site, navegue até a propriedade com a qual deseja começar.
Eu recomendo focar primeiro na versão principal do seu site. Ou seja, a versão que você vê quando tenta visitar seu site no navegador. Em última análise, porém, você desejará revisar todas as versões.
Observação: muitos sites redirecionam os usuários de uma versão para outra, então há uma boa chance de esta ser a única versão que o Google conseguirá rastrear e indexar. Portanto, terá a maioria dos problemas para você solucionar.
Você verá um painel mostrando seu desempenho de tendência em resultados de pesquisa, cobertura de índice e aprimoramentos. Clique em ABRIR RELATÓRIO no canto superior direito do gráfico de cobertura do Índice.
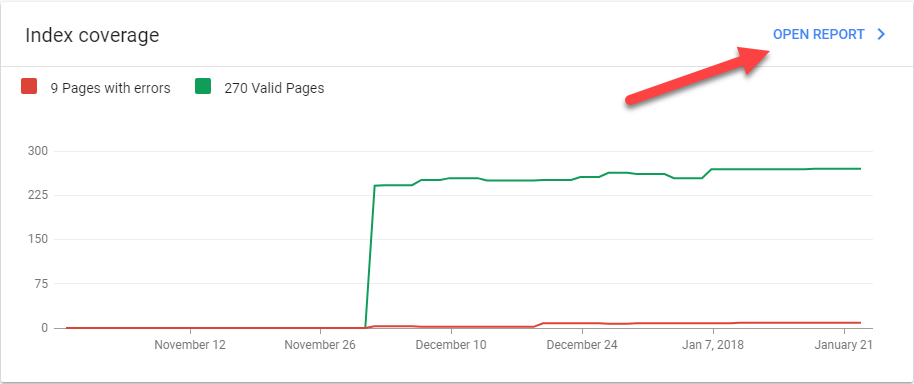
É aqui que você pode se aprofundar em todos os problemas técnicos que podem impedir que seu site tenha uma classificação mais alta nos resultados de pesquisa. Existem quatro tipos de problemas: Erro, Válido com avisos, Válido e Excluído .

Na seção abaixo, examinaremos cada um dos possíveis problemas que você provavelmente encontrará aqui em termos leigos e o que você deve fazer a respeito deles. A lista vem da documentação oficial do Google , cuja leitura também recomendamos fortemente.
Depois de acreditar que resolveu o problema, você deve informar o Google seguindo o fluxo de trabalho de resolução de problemas integrado à ferramenta. Descrevemos as etapas para fazer isso na parte inferior do artigo.
Os erros do Google Search Console são seu único problema de SEO? Baixe nossa lista de verificação de auto-auditoria de 187 pontos!Baixe Agora
Lista de erros do Google Search Console
Se o rastreador do Google, o Googlebot, encontrar um problema ao tentar rastrear seu site e não entender uma página do seu site, ele desistirá e seguirá em frente. Isso significa que sua página não será indexada e não ficará visível para os pesquisadores, o que afeta muito o desempenho da pesquisa.
Aqui estão alguns desses erros:
- Erro do servidor (5xx)
- erro de redirecionamento
- Bloqueado por robots.txt
- Marcado como ‘noindex’
- Suave 404
- Pedido não autorizado (401)
- Não encontrado (404)
- Problema de rastreamento
Concentrar seus esforços aqui é um ótimo lugar para começar.
Como corrigir um erro de servidor (5xx):
Seu servidor retornou um erro de nível 500 quando a página foi solicitada.
Um erro 500 significa que algo deu errado com o servidor de um site que o impediu de atender à sua solicitação. Nesse caso, algo em seu servidor impediu que o Google carregasse a página.
Primeiro, verifique a página em seu navegador e veja se consegue carregá-la. Se puder, há uma boa chance de o problema ter se resolvido sozinho, mas você deve confirmar.
Envie um e-mail para sua equipe de TI ou empresa de hospedagem e pergunte se o servidor sofreu alguma interrupção nos últimos dias ou se há alguma configuração que possa estar impedindo o Googlebot e outros rastreadores de acessar o site.
Como corrigir um erro de redirecionamento:
A URL foi um erro de redirecionamento. Pode ser um dos seguintes tipos: foi uma cadeia de redirecionamento muito longa; era um loop de redirecionamento; o URL de redirecionamento acabou excedendo o comprimento máximo do URL; havia um URL inválido ou vazio na cadeia de redirecionamento.
Isso basicamente significa que seu redirecionamento não funciona. Vá consertar!
Um cenário comum é que seu URL principal foi alterado algumas vezes, portanto, há redirecionamentos que redirecionam para redirecionamentos. Exemplo: http://seudominio.com redireciona para http://www.seudominio.com que então redireciona para https://www.seudominio.com.
O Google precisa rastrear uma tonelada de conteúdo, por isso não gosta de perder tempo e esforço rastreando esses tipos de links. Resolva isso garantindo que seu redirecionamento vá diretamente para o URL final, eliminando todas as etapas intermediárias.
URL enviado bloqueado por robots.txt:
Você enviou esta página para indexação, mas a página está bloqueada por robots.txt. Tente testar sua página usando o testador robots.txt.
Há uma linha de código em seu arquivo robots.txt que informa ao Google que não é permitido rastrear esta página, mesmo que você tenha solicitado ao Google para fazer exatamente isso ao enviá-la para ser indexada. Se você realmente deseja que ele seja indexado, localize e remova a linha do arquivo robots.txt.
Caso contrário, verifique seu arquivo sitemap.xml para ver se o URL em questão está listado lá. Se estiver, remova-o. Às vezes, os plug-ins do WordPress exibem páginas que não pertencem ao seu arquivo de mapa do site.
URL enviado marcado como ‘noindex’:
Você enviou esta página para indexação, mas a página tem uma diretiva ‘noindex’ em uma meta tag ou resposta HTTP. Se você deseja que esta página seja indexada, você deve remover a tag ou a resposta HTTP.
Você está enviando sinais confusos ao Google. “Me indexe… não, NÃO FAÇA!” Verifique o código-fonte da sua página e procure a palavra “noindex”. Se você o vir, acesse seu CMS e procure uma configuração que remova isso ou encontre uma maneira de modificar o código da página diretamente.
Também é possível não indexar uma página por meio de uma resposta de cabeçalho HTTP por meio de um X-Robots-Tag, que é um pouco mais complicado de detectar se você não se sentir confortável trabalhando com ferramentas de desenvolvedor. Você pode ler mais sobre isso aqui .
O URL enviado parece ser um Soft 404:
Você enviou esta página para indexação, mas o servidor retornou o que parece ser um soft 404.
Estas são as páginas que parecem estar quebradas para o Google, mas não estão mostrando corretamente uma resposta 404 Not Found. Estes tendem a borbulhar de duas maneiras:
- Você tem uma página de categoria sem conteúdo nessa categoria. É como uma prateleira vazia em uma mercearia.
- O tema do seu site está criando automaticamente páginas que não deveriam existir.
Você deve converter essas páginas em páginas 404 adequadas, redirecioná-las para seu novo local ou preenchê-las com algum conteúdo real.
Para saber mais sobre esse problema, leia nosso guia detalhado para corrigir erros Soft 404 .
A URL enviada retorna solicitação não autorizada (401):
Você enviou esta página para indexação, mas o Google obteve uma resposta 401 (não autorizada). Remova os requisitos de autorização para esta página ou permita que o Googlebot acesse suas páginas verificando sua identidade.
Esse aviso geralmente é acionado quando o Google tenta rastrear uma página que só pode ser acessada por um usuário conectado. Você não quer que o Google desperdice recursos tentando rastrear esses URLs, então você deve tentar encontrar o local em seu site onde o Google descobriu o link e removê-lo.
Para que isso seja “enviado”, ele precisaria ser incluído no seu mapa do site, então verifique primeiro.
URL enviado não encontrado (404):
Você enviou um URL inexistente para indexação.
Se você remover uma página do seu site, mas se esquecer de removê-la do mapa do site, provavelmente verá esse erro. Isso pode ser evitado com a manutenção regular do arquivo de mapa do site.
Guia de mergulho profundo: para saber mais sobre como corrigir esse erro, leia nosso artigo sobre como corrigir erros 404 em seu site .
O URL enviado tem um problema de rastreamento:
Você enviou esta página para indexação, e o Google encontrou um erro de rastreamento não especificado que não se enquadra em nenhum dos outros motivos. Tente depurar sua página usando a ferramenta de inspeção de URL.
Algo atrapalhou a capacidade do Google de baixar e renderizar totalmente o conteúdo da sua página. Tente usar a ferramenta Fetch as Google conforme recomendado e procure discrepâncias entre o que o Google renderiza e o que você vê quando carrega a página em seu navegador.
Se sua página depende muito de Javascript para carregar o conteúdo, esse pode ser o problema. A maioria dos mecanismos de busca ainda ignora o Javascript, e o Google ainda não é perfeito nisso. Um longo tempo de carregamento da página e recursos bloqueados são outros possíveis culpados.
Lista de avisos do Google Search Console
Os avisos não são tão graves quanto os erros, mas ainda requerem sua atenção. O Google pode ou não decidir indexar o conteúdo listado aqui, mas você pode aumentar as chances de seu conteúdo ser indexado e, potencialmente, melhorar sua classificação se resolver os avisos que o Google Search Console descobre.
Indexado, embora bloqueado por robots.txt:
A página foi indexada, apesar de estar bloqueada por robots.txt
Seu arquivo robots.txt é como um guarda de trânsito para os mecanismos de busca. Ele permite que alguns rastreadores acessem seu site e bloqueiem outros. Você pode bloquear rastreadores no nível do domínio ou página por página.
Infelizmente, esse aviso específico é algo que vemos o tempo todo. Geralmente acontece quando alguém tenta bloquear um bot ruim e coloca uma regra excessivamente rígida.
Abaixo está um exemplo de um local de música local que notamos estava bloqueando todos os rastreadores de acessar o site, incluindo o Google. Não se preocupe, nós os informamos sobre isso .

Bloqueado por robôs
Mesmo que o site permanecesse nos resultados de pesquisa, o snippet não era o ideal porque o Google não conseguia ver a tag de título, a meta descrição ou o conteúdo da página.
Então, como você conserta isso? Na maioria das vezes, esse aviso ocorre quando ambos estão presentes: um comando disallow em seu arquivo robots.txt e uma meta tag noindex no HTML da página. Você usou uma diretiva noindex para informar aos mecanismos de pesquisa que uma página não deve ser rastreada, mas também bloqueou os rastreadores de visualizar essas páginas em seu arquivo robots.txt. Se os rastreadores do mecanismo de pesquisa não puderem acessar esses URLs, eles não poderão ver a diretiva noindex.
Para remover esses URLs do índice e resolver o aviso Indexado, embora bloqueado pelo robots.txt , remova o comando de bloqueio para esses URLs no arquivo robots.txt. Os rastreadores verão a diretiva noindex e removerão essas páginas do índice.
Lista de URLs válidos do Google Search Console
Isso informa sobre a parte do seu site que é saudável. O Google rastreou e indexou com sucesso as páginas listadas aqui. Mesmo que esses não sejam problemas, daremos a você um breve resumo do que cada status significa.
Enviado e indexado:
Você enviou o URL para indexação e ele foi indexado.
Você queria a página indexada, então contou ao Google sobre isso e eles gostaram totalmente. Você conseguiu o que queria, então sirva-se de uma taça de champanhe e comemore!
Indexado, não enviado no mapa do site:
A URL foi descoberta pelo Google e indexada.
O Google encontrou essas páginas e decidiu indexá-las, mas você não facilitou tanto quanto poderia. O Google e outros mecanismos de pesquisa preferem que você os informe sobre o conteúdo que deseja indexar, incluindo-os em um mapa do site. Fazer isso pode aumentar potencialmente a frequência com que o Google rastreia seu conteúdo, o que pode se traduzir em classificações mais altas e mais tráfego.
Indexado; considere marcar como canônico:
A URL foi indexada. Como ele tem URLs duplicados, recomendamos marcar explicitamente esse URL como canônico.
Uma URL duplicada é um exemplo de página que pode ser acessada por meio de diversas variações, mesmo que seja a mesma página. Exemplos comuns incluem quando uma página é acessível com e sem barra invertida ou com uma extensão de arquivo no final. Algo como yoursite.com/index.html e yoursite.com, que levam à mesma página.
Isso é ruim para o SEO porque dilui qualquer autoridade que uma página acumule por meio de backlinks externos entre as duas versões. Ele também força um mecanismo de pesquisa a desperdiçar seus recursos rastreando vários URLs para uma única página e também pode tornar seus relatórios analíticos bastante confusos .
Uma tag canônica é uma única linha em seu HTML que informa aos mecanismos de pesquisa qual versão da URL eles devem priorizar e consolida todos os sinais de link para essa versão. Eles podem ser extremamente benéficos e devem ser considerados.
URLs excluídos do Google Search Console
Estas são as páginas que o Google descobriu, mas optou por não indexar. Na maioria das vezes, essas serão páginas que você disse explicitamente ao Google para não indexar. Outras são páginas que você pode realmente querer indexar, mas o Google optou por ignorá-las porque não foram consideradas valiosas o suficiente.
Bloqueado pela tag ‘noindex’:
Quando o Google tentou indexar a página, encontrou uma diretiva ‘noindex’ e, portanto, não a indexou. Se você não deseja que a página seja indexada, você o fez corretamente. Se você deseja que esta página seja indexada, você deve remover a diretiva ‘noindex’.
Este é bastante simples. Se você realmente deseja que esta página seja indexada, eles dizem exatamente o que você deve fazer.
Se você não deseja que a página seja indexada, nenhuma ação é necessária, mas convém evitar que o Google rastreie a página em primeiro lugar, removendo todos os links internos. Isso evitaria que os mecanismos de pesquisa desperdiçassem recursos em uma página na qual não deveriam gastar tempo e se concentrariam mais nas páginas que deveriam.
Bloqueado pela ferramenta de remoção de página:
A página está atualmente bloqueada por uma solicitação de remoção de URL.
Alguém em sua empresa pediu diretamente ao Google para remover esta página usando a ferramenta de remoção de página. Isso é temporário, portanto, considere excluir a página e permitir que ela retorne um erro 404 ou exigir um login para acessar, se desejar mantê-la bloqueada. Caso contrário, o Google pode optar por indexá-lo novamente.
Bloqueado por robots.txt:
Esta página foi bloqueada para o Googlebot com um arquivo robots.txt.
Se uma página for indexada nos resultados de pesquisa, mas de repente for bloqueada com um arquivo robots.txt, o Google normalmente manterá a página no índice por um período de tempo. Isso ocorre porque muitas páginas são bloqueadas acidentalmente e o Google prefere a diretiva noindex como o melhor sinal para saber se você deseja ou não excluir o conteúdo.
Se o bloqueio persistir por muito tempo, o Google descartará a página. Isso provavelmente ocorre porque eles não conseguirão gerar snippets de pesquisa úteis para o seu site se não puderem rastreá-lo, o que não é bom para ninguém.
Bloqueado devido a solicitação não autorizada (401):
A página foi bloqueada para o Googlebot por uma solicitação de autorização (resposta 401). Se você deseja que o Googlebot rastreie esta página, remova os requisitos de autorização ou permita que o Googlebot acesse suas páginas verificando sua identidade.
Um erro comum é criar links para páginas em um site de teste (staging.yoursite.com ou beta.yoursite.com) enquanto um site ainda está sendo construído, mas esquecer de atualizar esses links assim que o site entrar em produção.
Pesquise esses URLs em seu site e corrija-os. Você pode precisar da ajuda de sua equipe de TI para fazer isso se tiver muitas páginas em seu site. Ferramentas de rastreamento como Screamingfrog SEO Spider podem ajudá-lo a escanear seu site em massa.
Anomalia de rastreamento:
Ocorreu uma anomalia não especificada ao buscar este URL. Isso pode significar um código de resposta de nível 4xx ou 5xx.
Esse problema pode ser um sinal de um problema prolongado com seu servidor. Veja se a página está acessível em seu navegador e tente usar a ferramenta de inspeção de URL. Você pode querer verificar com sua empresa de hospedagem para confirmar se não há nenhum problema grave com a estabilidade do seu site.
Ao diagnosticar esse problema em muitos sites, descobrimos que os URLs em questão costumam ser:
- Uma parte de uma cadeia de redirecionamento
- Uma página que redireciona para uma página que retorna um erro 404
- Uma página que não existe mais e está retornando um erro 404
Se houver algo engraçado acontecendo com seus redirecionamentos, você deve limpar isso. Certifique-se de que haja apenas uma etapa no redirecionamento e que a página para a qual seu URL está apontando carregue corretamente e retorne uma resposta 200. Depois de corrigir o problema, certifique-se de voltar e buscar como Google para que seu conteúdo seja rastreado novamente e indexado.
Se a página retornar um 404, verifique se você não está tendo problemas de velocidade ou servidor.
Rastreado – atualmente não indexado:
A página foi rastreada pelo Google, mas não indexada. Pode ou não ser indexado no futuro; não há necessidade de reenviar este URL para rastreamento.
Se você vir isso, dê uma boa olhada em seu conteúdo. Ele responde à consulta do pesquisador? O conteúdo é preciso? Você está oferecendo uma boa experiência para seus usuários? Você está ligando para fontes confiáveis? Alguém mais está ligando para ele?
Certifique-se de fornecer uma estrutura detalhada de todo o conteúdo da página que precisa ser indexado por meio do uso de dados estruturados . Isso permite que os mecanismos de pesquisa não apenas indexem seu conteúdo, mas também que ele apareça em consultas futuras e possíveis snippets em destaque.
A otimização da página pode aumentar as chances de o Google optar por indexá-la na próxima vez que ela for rastreada.
Descoberto – atualmente não indexado:
A página foi encontrada pelo Google, mas ainda não foi rastreada.
Mesmo que o Google tenha descoberto a URL, não sentiu que era importante o suficiente para perder tempo rastreando. Se você deseja que esta página receba tráfego de pesquisa orgânica, considere criar mais links para ela em seu próprio site. Certifique-se de promover esse conteúdo para outras pessoas com a esperança de ganhar backlinks de sites externos. Os links externos para o seu conteúdo são um sinal para o Google de que uma página é valiosa e considerada confiável, o que aumenta as chances de ela ser indexada.
Página alternativa com tag canônica adequada:
Esta página é uma duplicata de uma página que o Google reconhece como canônica e aponta corretamente para essa página canônica, então nada para você fazer aqui!
Assim como a ferramenta diz, não há realmente nada a fazer aqui. Se te incomoda que a mesma página seja acessível por mais de uma URL, veja se existe uma forma de consolidar.
Duplicar sem canônico selecionado pelo usuário::
Esta página tem duplicatas, nenhuma das quais está marcada como canônica. Achamos que esta página não é a canônica. Você deve marcar explicitamente o canônico para esta página.
O Google está adivinhando qual página você deseja indexar. Não faça adivinhar. Você pode informar explicitamente ao Google qual versão de uma página deve ser indexada usando uma tag canônica.
Página não HTML duplicada:
Uma página não HTML (por exemplo, um arquivo PDF) é uma duplicata de outra página que o Google marcou como canônica.
O Google descobriu um PDF em seu site que continha as mesmas informações de uma página HTML normal, então eles optaram por indexar apenas a versão HTML. Geralmente, isso é o que você deseja que aconteça, portanto, nenhuma ação deve ser necessária, a menos que, por algum motivo, você prefira que eles usem a versão em PDF.
Duplicado, o Google escolheu canônico diferente do usuário:
Este URL é marcado como canônico para um conjunto de páginas, mas o Google acha que outro URL é um canônico melhor.
O Google discorda de você sobre qual versão de uma página eles devem indexar. A melhor coisa que você pode fazer é certificar-se de ter tags canônicas em todas as páginas duplicadas, de que essas canônicas sejam consistentes e de que você esteja vinculando apenas internamente à sua canônica. Tente evitar o envio de sinais mistos.
Vimos isso acontecer quando um site especifica uma versão de uma página como canônica, mas redireciona o usuário para uma versão diferente. Como o Google não pode acessar a versão que você especificou, talvez suponha que você cometeu um erro e substitui sua diretiva.
Não encontrado (404):
Esta página retornou um erro 404 quando solicitada. A URL foi descoberta pelo Google sem nenhuma solicitação explícita para ser rastreada.
Erros não encontrados ocorrem quando o Google tenta rastrear um link ou URL indexado anteriormente para uma página que não existe mais. Muitos erros 404 na web são criados quando um site muda seus links, mas esquece de configurar redirecionamentos da versão antiga para a nova URL.
Se existir uma substituição para a página que aciona o erro 404 em seu site, você deve criar um redirecionamento 301 permanente do URL antigo para o novo URL. Isso evita que o Google e seus usuários vejam a página 404 e experimentem um link quebrado. Ele também pode ajudá-lo a manter a maior parte do tráfego de pesquisa que estava indo para a página antiga.
Se a página não existir mais, continue permitindo que a URL retorne um erro 404, mas tente eliminar todos os links para ela. Ninguém gosta de links quebrados.
Página removida devido a reclamação legal:
A página foi removida do índice devido a uma reclamação legal.
Se o seu site foi hackeado e infectado com código malicioso, há uma boa chance de você ver muitos desses problemas surgindo em seus relatórios. Os hackers adoram criar páginas para downloads ilegais de torrents de filmes e medicamentos prescritos, que os departamentos jurídicos de grandes corporações procuram e registram reclamações.
Se você receber um desses, remova imediatamente o material protegido por direitos autorais e certifique-se de que seu site não foi invadido. Certifique-se de que todos os plug-ins estejam atualizados, que suas senhas estejam seguras e que você esteja usando a versão mais recente do seu software CMS.
Página com redirecionamento:
A URL é um redirecionamento e, portanto, não foi adicionada ao índice.
Se você vincular a uma versão antiga de um URL que redireciona para um novo, o Google ainda detectará esse URL e o incluirá no Relatório de cobertura. Considere atualizar qualquer link usando a versão antiga do URL para que os mecanismos de pesquisa não sejam forçados a passar por um redirecionamento para descobrir seu conteúdo.
Na fila para rastreamento:
A página está na fila de rastreamento; verifique novamente em alguns dias para ver se ele foi rastreado.
Esta é uma boa notícia! Espere ver seu conteúdo indexado nos resultados de pesquisa em breve. Vá ao micro-ondas um saco de pipoca e volte daqui a pouco. Use esse tempo de inatividade para limpar todos os outros problemas incômodos que você identificou no relatório de cobertura do índice.
Suave 404:
A solicitação de página retorna o que pensamos ser uma resposta 404 suave.
Aos olhos do Google, essas páginas são uma casca do que eram antes. Os resquícios de algo útil que já existiu, mas não existe mais. Você deve convertê-los em páginas 404 ou começar a preenchê-los com conteúdo útil.
URL enviado descartado:
Você enviou esta página para indexação, mas ela foi retirada do índice por um motivo não especificado.
A descrição deste problema é bastante vaga, por isso é difícil dizer com certeza qual ação você deve tomar. Nosso melhor palpite é que o Google analisou seu conteúdo, experimentou por um tempo e decidiu não incluí-lo mais.
Investigue a página e critique sua qualidade geral. A página é fina? Desatualizado? impreciso? Demora para carregar? Ele foi negligenciado por anos? Seus concorrentes lançaram algo infinitamente melhor?
Tente atualizar e melhorar o conteúdo e garantir alguns novos links para a página. Isso pode levar a uma reindexação da página.
Duplicado, URL enviado não selecionado como canônico:
O URL faz parte de um conjunto de URLs duplicados sem uma página canônica explicitamente marcada. Você solicitou explicitamente que este URL fosse indexado, mas como é uma duplicata e o Google acredita que outro URL é um candidato melhor para canônico, o Google não indexou este URL. Em vez disso, indexamos o canônico que selecionamos.
O Google rastreou um URL que você solicitou explicitamente, mas também disse ao Google que uma duplicata da página era realmente aquela que deveria indexar e prestar atenção.
Decida qual versão você deseja indexar, defina-a como canônica e, em seguida, tente dar preferência a essa versão ao vincular a uma página no conjunto de duplicatas, tanto internamente em seu próprio site quanto externamente.
Como navegar no relatório de usabilidade móvel
À medida que o tráfego da Web e as pesquisas diárias ocorrem cada vez mais em dispositivos móveis, o Google e outros mecanismos de pesquisa têm dado um foco maior à importância da usabilidade móvel ao determinar as classificações de uma página.
O relatório de usabilidade móvel no Google Search Console ajuda você a identificar rapidamente problemas de compatibilidade com dispositivos móveis que podem estar prejudicando a experiência do usuário e impedindo que seu site obtenha mais tráfego orgânico.
Na seção abaixo, analisamos alguns dos problemas mais comuns detectados neste relatório e como você pode trabalhar para resolvê-los.
Quando sua página usa plugins incompatíveis
A página inclui plug-ins, como Flash, que não são suportados pela maioria dos navegadores móveis. Recomendamos projetar sua aparência e animações de página usando tecnologias modernas da web.
Em 2017, a Adobe anunciou que deixaria de oferecer suporte ao Flash até o final de 2020. Esse foi um dos pregos finais no caixão do Flash, que não era compatível com dispositivos móveis e estava repleto de problemas de segurança. Hoje, existem melhores tecnologias abertas da Web que são mais rápidas e mais eficientes em termos de energia do que o Flash.
Para corrigir esse problema, você precisará substituir seu elemento Flash por uma solução moderna como HTML5 ou remover o conteúdo completamente.
Janela de visualização não definida
A página não define uma propriedade viewport, que informa aos navegadores como ajustar a dimensão e a escala da página para se adequar ao tamanho da tela. Como os visitantes do seu site usam uma variedade de dispositivos com tamanhos de tela variados – de grandes monitores de desktop a tablets e pequenos smartphones – suas páginas devem especificar uma viewport usando a tag meta viewport.
A “janela de visualização” é a maneira técnica que seu navegador usa para dimensionar corretamente as imagens e outros elementos do seu site para que tenham uma ótima aparência em todos os dispositivos. A menos que você seja experiente em HTML, isso provavelmente exigirá a ajuda de um desenvolvedor. Se você quiser tentar, este guia pode ser útil.
Janela de visualização não definida como “largura do dispositivo”
A página define uma propriedade de viewport de largura fixa, o que significa que ela não pode ser ajustada para diferentes tamanhos de tela. Para corrigir esse erro, adote um design responsivo para as páginas do seu site e defina a janela de visualização para corresponder à largura e escala do dispositivo de acordo.
Nos primeiros dias do design responsivo, alguns desenvolvedores preferiam ajustar o site para experiências móveis em vez de torná-lo totalmente responsivo. A janela de visualização de largura fixa é uma ótima maneira de fazer isso, mas à medida que mais e mais dispositivos móveis entram no mercado, essa solução se torna menos atraente.
O Google agora favorece experiências responsivas na web. Se você está enfrentando esse problema, é provável que esteja frustrando alguns de seus usuários móveis e possivelmente perdendo algum tráfego orgânico. Pode ser hora de ligar para uma agência ou contratar um desenvolvedor para tornar seu site responsivo.
Conteúdo mais largo que a tela
A rolagem horizontal é necessária para ver palavras e imagens na página. Isso acontece quando as páginas usam valores absolutos em declarações CSS ou usam imagens projetadas para ter uma aparência melhor em uma largura específica do navegador (como 980px). Para corrigir esse erro, certifique-se de que as páginas usem valores relativos de largura e posição para elementos CSS e certifique-se de que as imagens também possam ser dimensionadas.
Isso geralmente ocorre quando há uma única imagem ou elemento em sua página que não está dimensionada corretamente para dispositivos móveis. No WordPress, isso geralmente pode ocorrer quando uma imagem recebe uma legenda ou um plug-in é usado para gerar um elemento que não é nativo do seu tema.
A maneira fácil de corrigir esse problema é simplesmente remover a imagem ou o elemento que não está dimensionado corretamente em dispositivos móveis. A maneira correta de corrigi-lo é modificar seu código para tornar o elemento responsivo.
Texto muito pequeno para ler
O tamanho da fonte da página é muito pequeno para ser legível e exigiria que os visitantes móveis “apertassem para ampliar” para ler. Depois de especificar uma janela de visualização para suas páginas da Web, defina os tamanhos de fonte para dimensionar adequadamente na janela de visualização.
Simplificando, seu site é muito difícil de ler em dispositivos móveis. Para experimentar isso em primeira mão, basta carregar a página em questão em um smartphone e experimentá-la em primeira mão.
De acordo com o Google, uma boa regra é fazer com que a página exiba não mais que 70 a 80 caracteres (cerca de 8 a 10 palavras) por linha em um dispositivo móvel. Se você estiver vendo mais do que isso, contrate uma agência ou desenvolvedor para modificar seu código.
Elementos clicáveis muito próximos
Este relatório mostra os URLs de sites nos quais os elementos de toque, como botões e links de navegação, estão tão próximos uns dos outros que um usuário móvel não pode tocar facilmente em um elemento desejado com o dedo sem também tocar em um elemento vizinho. Para corrigir esses erros, certifique-se de dimensionar e espaçar corretamente os botões e links de navegação para que sejam adequados para seus visitantes móveis.
Já visitou um site não responsivo com links tão pequenos que era IMPOSSÍVEL de usar? É disso que se trata esta questão. Para ver o problema em primeira mão, tente carregar a página em um dispositivo móvel e clique como se você fosse um de seus clientes. Se for difícil navegar de uma página para outra e a experiência exigir que você amplie antes de clicar, pode ter certeza de que tem um problema.
O Google recomenda que os elementos clicáveis tenham um tamanho de toque direcionado de cerca de 48 pixels, que geralmente é cerca de 1/3 da largura de uma tela ou aproximadamente o tamanho do dedo de uma pessoa. Considere substituir links de texto pequenos por botões grandes como uma solução fácil.
Como navegar no relatório de principais métricas da Web
É importante que você identifique e corrija quaisquer problemas que possam interferir na capacidade do Google de rastrear e classificar seu site, mas o Google também leva em consideração se seu site oferece uma boa experiência ao usuário.
O relatório Core Web Vitals no Google Search Console zera a velocidade da página. Ele se concentra nas principais métricas de velocidade da página que medem a qualidade da experiência do usuário para que você possa identificar facilmente quaisquer oportunidades de melhoria e fazer as alterações necessárias em seu site.
Para todos os URLs em seu site, o relatório exibe três métricas (LCP, FID e CLS) e um status (Ruim, Precisa melhorar ou Bom).
Aqui estão os parâmetros do Google para determinar o status de cada métrica.
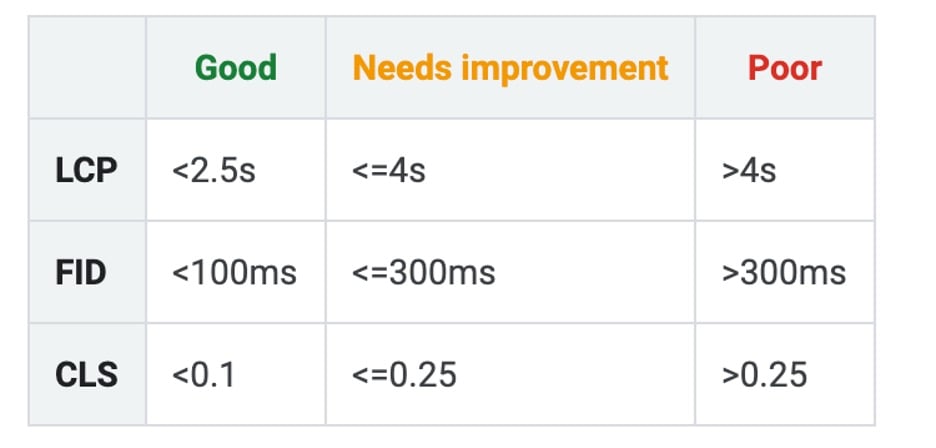
Vamos dar uma olhada em cada uma das três métricas e como melhorar cada uma delas.
- Largest Contentful Paint (LCP) : a quantidade de tempo que leva para exibir o maior elemento de conteúdo da página para o usuário depois de abrir o URL
- First Input Delay (FID) : A quantidade de tempo que leva para o navegador responder a uma interação (como clicar em um link) pelo usuário
- Deslocamento de layout cumulativo (CLS) : uma medida da frequência com que o layout do seu site é alterado inesperadamente, resultando em uma experiência de usuário insatisfatória
Maior pintura de conteúdo (LCP)
Largest Contentful Paint (LCP) refere-se à quantidade de tempo que leva para exibir o maior elemento de conteúdo da página para o usuário depois de abrir a página. Se o elemento principal não carregar dentro de um período de tempo razoável (menos de 2,5s), isso contribui para uma experiência ruim do usuário, visto que nada está sendo preenchido na tela.
Primeiro atraso de entrada (FID)
First Input Delay (FID) é uma medida de quanto tempo leva para o navegador responder a uma interação do usuário (como clicar em um link, etc.). Essa é uma métrica valiosa, pois é uma representação direta da capacidade de resposta do seu site. É provável que um usuário fique frustrado se os elementos interativos em uma página demorarem muito para responder.
Mudança cumulativa de layout (CLS)
Mudança cumulativa de layout (CLS) é uma medida de quantas vezes o layout do seu site muda inesperadamente durante a fase de carregamento. O CLS é importante porque as alterações de layout que ocorrem enquanto um usuário está tentando interagir com uma página podem ser incrivelmente frustrantes e resultar em uma experiência de usuário insatisfatória.
Aprimorando os Principais Pontos Vitais da Web
Uma maneira simples de verificar essas métricas no nível da página e identificar rapidamente as correções é utilizar o Chrome DevTools.
Depois de identificar uma página com um problema no Google Search Console, navegue até o URL dessa página e pressione Control+Shift+C (Windows) ou Command+Shift+C (Mac). Como alternativa, você pode clicar com o botão direito do mouse em qualquer lugar da página e clicar em “Inspecionar”.
A partir daí, você deve navegar até a opção de menu “Farol”.
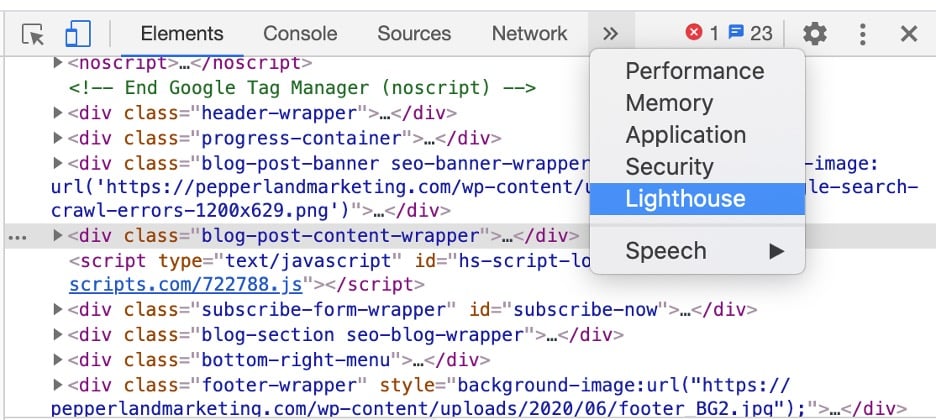
O Lighthouse auditará a página e gerará um relatório, pontuando o desempenho da página em 100. Você encontrará medições para LCP, FID e CLS, além de outras métricas úteis de velocidade da página.
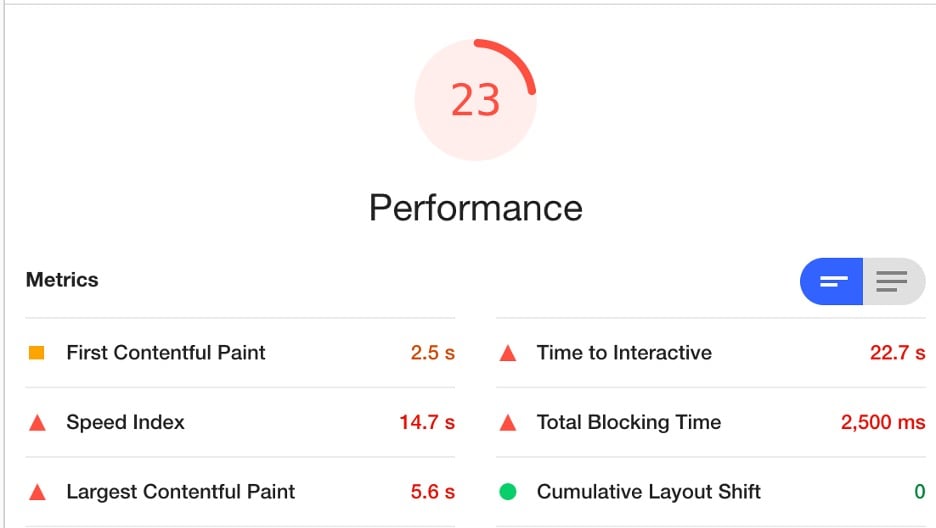
A melhor parte do Google Lighthouse é que ele fornece recomendações acionáveis para melhorar as métricas acima, juntamente com a economia estimada.
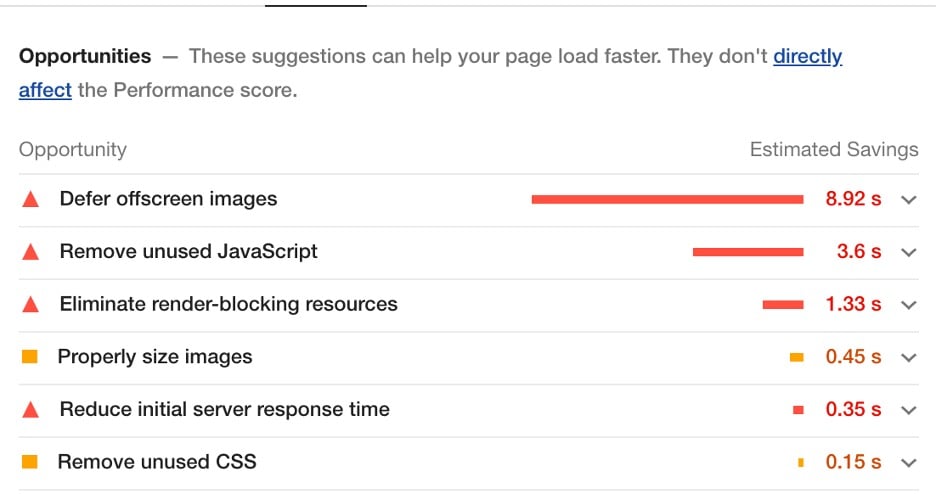
Trabalhe com seu desenvolvedor para implementar as alterações recomendadas sempre que possível.
Como dizer ao Google que você corrigiu um problema
Ao navegar por cada problema, você notará que clicar no URL de uma página abrirá um novo painel no lado direito da tela.
Percorra esta lista e certifique-se de que está satisfeito com o que vê. O Google colocou esses links aqui por um motivo: eles querem que você os use.
Se ainda tiver certeza de que o problema foi resolvido, você pode concluir o processo clicando em VALIDAR CORREÇÃO.
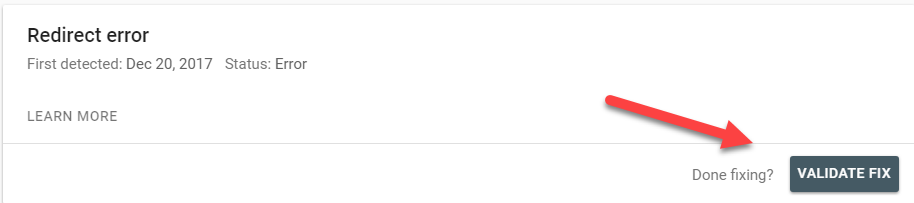
Nesse ponto, você receberá um e-mail do Google informando que o processo de validação foi iniciado. Isso levará de vários dias a várias semanas, dependendo do número de problemas que o Google precisa rastrear novamente.